Mutually Assured Recursion
 Artwork by my good friend Sophia Wood
Artwork by my good friend Sophia Wood
As we enter this fantastic and bizarre age of Artificial Intelligence, we are rapidly coming to grips with philosophical questions that were reserved for heady academic discussions just a few years ago. The nature of consciousness continues to elude us, but novel experiences born from scientific progress in recent years begins to elucidate a larger picture of the world that is more monistic than anthropocentric. At both ends of the spectrum, we are seeing an underlying information architecture that forms an emergent foundation for sentience and qualia. Join me for a brief journey into recent advancements and how blurred the lines are between disparate subjects of mathematics, neuroscience, physics, computability, and philosophy.
Compression
Our journey begins with a simple question: what do we mean when we talk about information? In his seminal text Gödel Escher Bach, Hofstadter asserts that meaning itself is a strange dance between content and interpretation. For there to be information, and therefore meaning, there must be an interpreter. In isolation, interpretation and content are interchangeable. Imagine a strange world where, instead of DNA producing different organisms through the biology of life, DNA was the same for all life and the biological decoding systems present in zygotes were the differentiating factors. For example, the difference between a frog and a cat would be contained in the decoding mechanisms themselves, and that the genetic information no longer lies in the DNA. The fact that the decoding systems for DNA are universal (meaning they are common and behave predictably the same) but DNA is variable makes DNA the content and the decoding systems the interpretation.
This concept of meaning can be made more abstract with the introduction of Turing Machines, which I have covered in my other posts in this series. The important takeaway is that we have a model for an entity that takes in information and that can process that information to produce a result. An important thought experiment and philosophical discussion is whether or not Turing Machines are the canonical model for all information processing. This is to ask: are there answerable questions that could not be answered using a Turing Machine alone? Our best answer to this question is the Church Turing Thesis, and the current consensus is that the answer is no: all questions with answers that can be reached via Effective Methods can be computed on a Turing Machine. This is to say any algorithm from integers to integers, or from strings to strings that has a method for conveying the former from the latter is computable.
Compression of Meaning
Earlier this year, a paper was published demonstrating a surprising result. The researchers were able to perform text classification using only text compression and a clustering algorithm (kNN). This task classically requires fairly advanced machine learning tools such as neural networks, symbolic analysis, large language models, vectorization approaches, or decision trees. Yet, despite being remarkably simple, the compression based approach beat many existing models for text classification. Their approach involved building a similarity metric by comparing the compressed size of two strings of text \(A\) and \(B\), and their concatenation \(A + B\) , which was a means of determining cross-entropy or roughly the average information shared between the two strings. This is actually similar to the method that I used in my other post to classify emergent behavior in Cellular Automata using PNG image compression and the UMAP dimensionality reduction algorithm.
Compression may seem to be a prosaic topic, but the longer one spends studying it, the more one sees that it is anything but. Marcus Hutter, creator of the Hutter Prize, is a champion of this philosophy. The prize is awarded to any daring mind who can beat the current record for compressing human knowledge (as measured by compression ratio of a download of Wikipedia). Hutter created this prize to incentivize the advancement of artificial intelligence, and those who run the challenge believe that there is no difference between compression and AI. When viewed from the perspective of meaning and interpretation, compression is the art of distilling the meaning of something to its essence. This will forever remain an art, as devising a technique to find the best compression scheme is impossible to develop. Much like the Halting Problem, and the undecidability of the Continuum Hypothesis, the perfection of meaning is unattainable and yet it seems that if it weren’t, it would not be able to exist at all.
Critical Brain Hypothesis
Another concept critical to the study of information theory is that of communication. It is not enough for information to exist in isolation, it must be able to be interpreted. The separation of interpreter and content implies that there is some distance between the two, either spatially, temporally, or semantically. In any case, there is some notion of durability along with momentum that equips structure with the ability to be interpreted. No current school of thought is better poised to study this topic than Self Organized Criticality, which has yielded an incredibly promising theory of how communication and consciousness may arise as an emergent property of large interacting systems.
This new concept is known as the Critical Brain Hypothesis, and it may have laid a foundation for understanding neuroscience from the standpoint of physics and information theory. The hypothesis posits that the brain, and all brains, operate near a critical point in a phase transition from a comatose state of inactivity to a seizure state of chaos. (or more simply, order to disorder) Much like other theories in science, this is deceptively obvious at first glance. The brain must be operating in such a state, otherwise we would either be comatose or seizing. The fact that we are in such an intermediate state is not where the concept of the theory lies. Rather, it is observing what phenomenon occur when this is the case. In particular, being in this intermediate state not only ensures that we are not dead, but it also optimizes the distance which information can travel, how much of it can be processed and stored, and our ability to process a high dynamic range of sensory input.
The Emergence of Communication
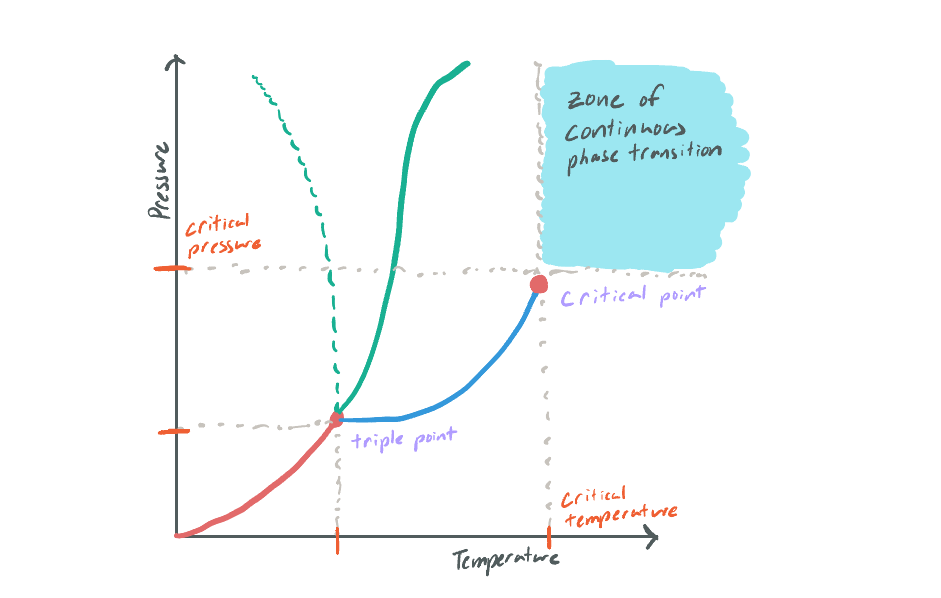
Critical points arise when there is a continuous phase transition in a system between two states. When water boils, it undergoes a phase transition from liquid to gas instantaneously. There is no intermediate liquid-gas hybrid at standard temperature and pressure. Yet, if you pressurize and heat a chamber to supercritical levels, you can enter a state where this intermediate phase between water and gas is possible. This critical point is where the hypothesis gets its name from, but the critical “point” it refers to is the midpoint between the two phases in any continuous phase transition.
Another useful model to study in the topic of criticality is the Ising Model of magnetism which is a model for simulating how metals magnetize. At the microscopic scale, metals are comprised of crystalline structure involving many particles. The phases in this system are “not magnetized” and “magnetized” and there are plenty of intermediate configurations of the system that will result in varying degrees of magnetization. Each individual particle in the crystal lattice has its own magnetic polarization, and each particle will exert some force over its neighbors due to its magnetic field exerting a force on their magnetic moment (and vice-versa). As a whole, the metal is most magnetized when all of its particles exist in the same orientation (which would also be the lowest energetic state, as neighbors would exert almost no force on each other).
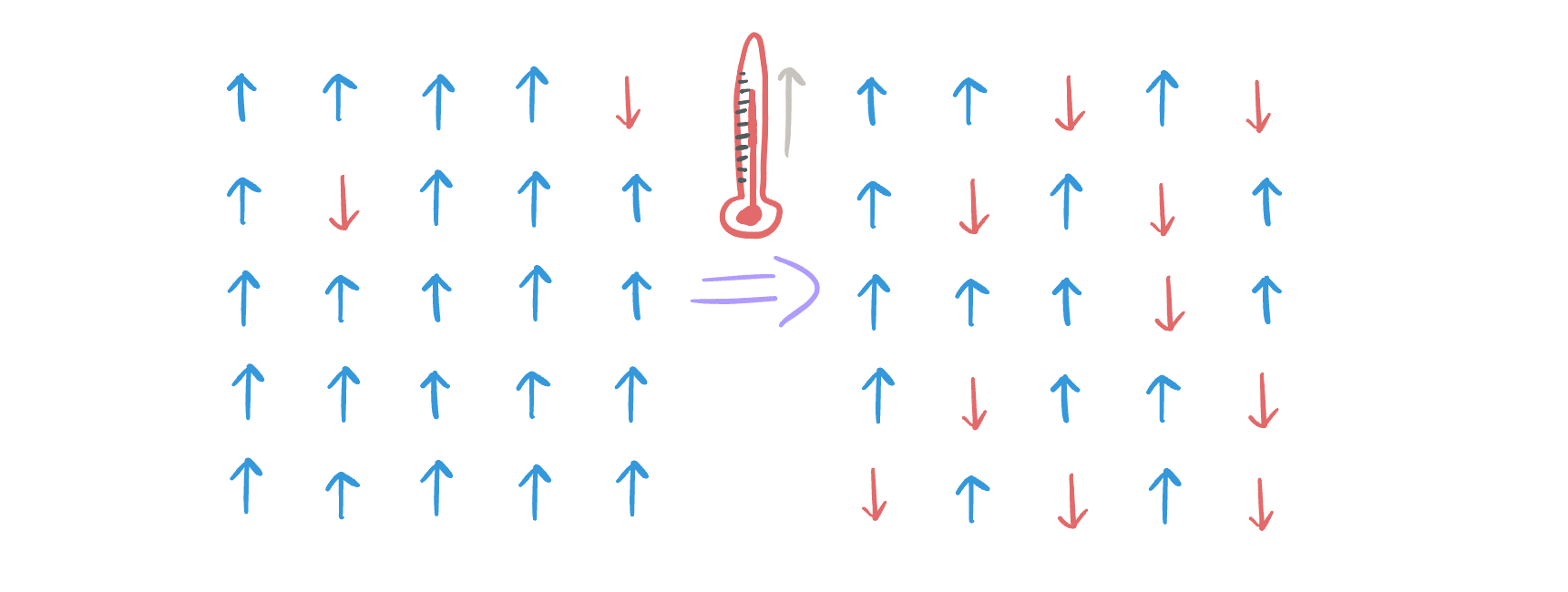
As in the earlier case of water, we introduce a control parameter of temperature which will affect the phase of our system. As the application of heat to a system will increase the kinetic energy of its particles, the hotter the lattice becomes, the more the particles will move (sporadically and randomly). These random fluctuations eventually overcome the strength of aligned magnetism of the particles in the system and it enters a de-magnetized state. This is known as the Curie Temperature and can be demonstrated experimentally by heating up a permanent magnet until it demagnetizes.
As magnetic particles exert force on each other, a question we can ask is “How far does the effect of one particle changing orientation travel?”. This is an interesting question for our exploration because a particle flipping is one bit of information, and in this simple model we can easily find the probability that it is able to affect some other particle in the system some distance away. We can define a notion of “correlation length” being the maximal distance that two particles can remain correlated with each other. I will not go into the math here, but I will share the correlation length as a function of temperature:
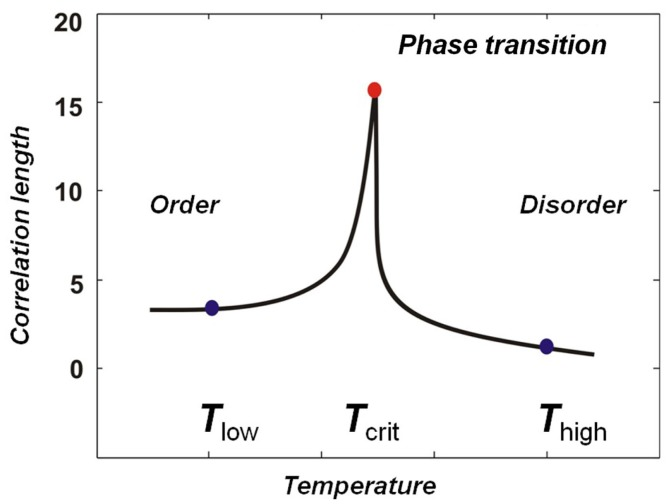 Figure from John M. Beggs’ paper - DO 10.3389/fphys.2012.00163
Figure from John M. Beggs’ paper - DO 10.3389/fphys.2012.00163
What we find is that correlation distance is not only maximized at the critical temperature, but that in an ideal model it actually becomes infinite. To highlight the importance of that discovery, for a moment imagine a magnet the size of the Earth, or even the solar system. If that magnet were to be uniformly heated to its critical temperature, you could flip a single particle on one side and reliably be able to detect its effect on the other side.
Scale Free Properties
What is perhaps even more surprising than the ability to transmit information across vast distances solely through the interaction of adjacent elements in a system is what happens to the structure of the system as a whole at the critical point. If you observe the distribution of clusters of particles in one orientation or another, you will find that the entire system becomes scale-free. That is to say that no matter what scale you are observing the system at, you will see the same patterns arise. This would be like opening up Google Earth and being able zoom to a random level of magnification, yet not being able to tell that anything had changed. This fractal property exists only at the temperature is at the critical point. Below that temperature, and as you zoom out the system becomes homogenous. Above that temperature, and as you zoom out the system becomes chaotic and random.
Simulation and Animation by Douglas Ashton
If you read further on the Critical Brain Hypothesis, you will see why this scale-free property is not only interesting but also incredibly useful. It is the reason we are able to respond to slight and major sensory inputs with the same neural structures. These scale-free properties also offer up a new way of measuring when a system is at the critical point. Another way of defining a scale-free system is to say that the distribution of its structures (either in size or in time) follow a Power Law. When a system is at the critical point, it will demonstrate power-law distribution of its structure. The inverse, however, is not always true. Still, from experimental evidence we have so far it is often the case that when we observe the power law arising in nature it implies that some system is operating near a critical point.
Branching Model and Universality
Our brains are not magnets, obviously, so an argument involving the Ising Model is insufficient to motivate further discussion on the nature of mind. Thankfully, John M. Beggs and Nicholas Timme (the original authors of the paper forwarding the Critical Brain Hypothesis) were able to determine a control parameter for neural networks. If, instead of temperature, we observed some metric of connectivity in a neural network, we can find a critical point that satisfies all of our definitions.
In Neuroscience and the study of neural networks, there is a useful tool known as the branching model. It models neurons in layers of a network that have input from neurons in the previous layer, and output their activation to neurons in the next layer. The control parameter that we want to use is called the branching ratio \(\beta\), or (on average) how many neurons are activated downstream when a single neuron fires. This is equivalent to the sum of probabilities that each downstream neuron will fire given the source neuron has fired. For example, if the \(\beta = 1\), then each neuron firing on average produces one activation downstream.
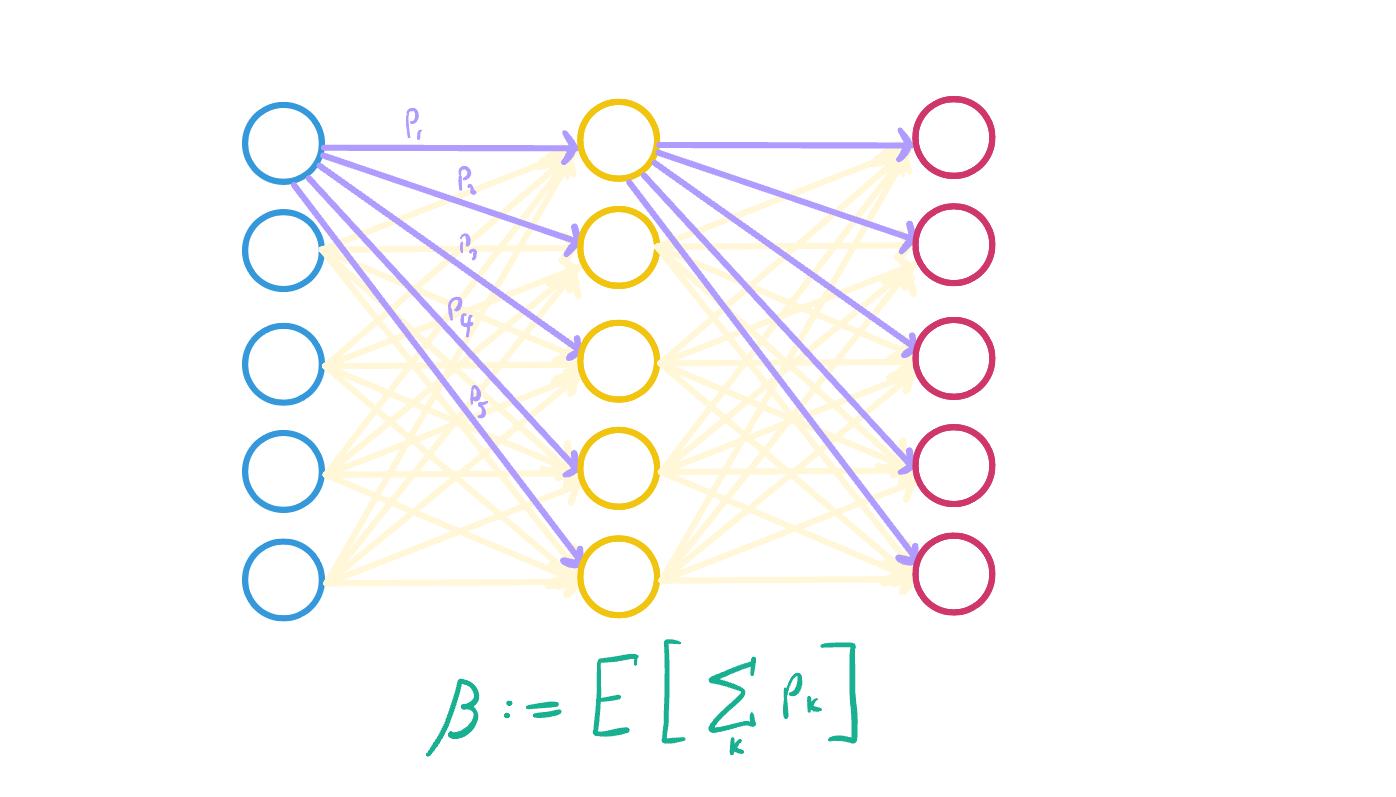
It turns out that the critical point of neural networks occurs when \(\beta = 1\), at which point the correlation distance in a neural network diverges (and thus becomes infinite) and the distribution of structure on that network becomes scale free. The structure, in this case, is the length of so-called “Neuronal Avalanches” which are clusters of neurons that fire one after another surrounded by periods of no neural activity. The size (number of involved neurons) and length (duration of avalanche) are both power law distributed, meaning that there is no characteristic scale for neural activity. This has been verified experimentally in hundreds of experiments using many methods of measurement on many species (including humans).
Universality
A practical result of the Critical Brain Hypothesis is that the results are beautifully abstract. We chose to call the interacting agents in our system “neurons” because we wished to discuss the brain, but we could have just as easily called them “people in social networks”, or “stock markets”, or even “coffee grounds”. It turns out that not only are the things I mentioned often operating near critical points, but their power law distributions have the same characteristic exponents. This is to say that minds, social groups, financial markets, and even the percolation of coffee through coffee grounds in espresso have the same fractal structure as identified by the distribution of the structure that emerges when they operate near criticality.

These are referred to as universality classes, of which the one we are referring to is Directed Percolation. These abstract classes of systems are one way of teasing out emergence from the systems that produce them. Much like equivalent models of computation, the abstract process itself and the structure it conveys does not depend on the models used to describe it. Or, at least if the Church Turing Thesis holds that is. While these two concepts are different, it is hard not to marvel at the similarities that we begin to observe when we find that emergence is less like a study of species and more like a study of snowflakes.
Free Will
To continue this journey, I have to make a brief detour through the concept of free will. I don’t think there is a more contentious and ill-defined philosophical topic to discuss, but it is nonetheless one of the more important topics when we speak of intelligence and cognition. To be precise going forward, when I say free will, I mean the notion that given the exact same configuration of all state in a system that a conscious being could non-deterministically decide to act in more than one way. Whether or not you believe in this notion of free will, I invite you to live in this hypothetical where it does not exist for the sake of exploring the consequences.
The Stance of Science
The general consensus of the neuroscience field is that free will does not exist. Indeed, from a physics perspective we live in a world where all but quantum indeterminancy is deterministic. Some still argue that the indeterminism of quantum mechanics affords enough breathing room for free will, but we have far more empirical evidence to at least indicate that the majority of our actions are not of our own agency. Also, it is not enough for something to be unpredictable for it to imply free will. Indeterminacy leads to free will only when its results are attributable to the emergent properties of consciousness. Since quantum fluctuation happens on such a small scale (and a lower level of abstraction than neural systems), there would have to be profound justification to indicate that the conscious being containing those particles would be exerting control over those fluctuations.
Even more damning, quantum entanglement is incapable of transmitting information. We can look to hallmark discoveries in the field of quantum mechanics such as Bell’s Theorem which show that while particles can indeed be linked at arbitrary distance, no information can be transmitted between them. If one particle is measured to be in one state, it will reliably predict the state of the entangled pair, but there is no way to control what state it will resolve to. This leads to a system that is correlated, but not predictable or able to be influenced a-priori.
Compatibilism
Even if free will is somewhat of an illusion, we have lived our whole lives up to this point without needing to worry about whether or not we have it. Our perception that we have agency over our decisions is enough, which is the wisdom that compatibilism brings. It is not necessary for this journey to agree with compatibilism, but I wanted to include this to show that we are not being extremist in our opinions of free will. It is possible to hold a perspective that both rejects physical agency yet permits the perception that we still have it. While it may seem like the most grandiose cognitive dissonance, I argue that it is axioms like these that make daily life and social existence as a perceived entity separate from the world possible. Once again, like the Halting Problem or incompatibility of Kolmogorov Complexity, the nuanced meaning and beauty of life lives in the tension between structure and paradox.
Large Language Models
Most everyone reading this has been part of the collective shock and awe in witnessing the dawn of large language models and the rapid advancement of artificial intelligence in 2023. These models have existed for years, but only recently have we developed both the architecture and computational resources to train these models effectively. I have watched with morbid curiosity as researchers move from opinions that these systems are simply copying from their training data, to opinions that would have previously seemed outlandish just a year ago.
These systems are not inherently complex in their architecture. GPT, the most well-known large language model today, is built using an attention model, transformers, some feed-forward neural networks, and special encoding for inputs. This is a dramatic simplification, but I stress that the actual structure of these systems is not ornate. This is why researchers were so quick to initially write off the convincing results of GPT as explainable and only a mirror of the input data it was trained on. Yet, one by one, many of the things we thought to be impossible with such a conceived system began to be disproven.
It began when large language models developed a theory of mind, which seemed to imply that the networks somehow encoded that entities could have knowledge of their own separate from others. Then we found that not only could these models conduct scientific research by designing and performing experiments, but that they demonstrated power-seeking behaviors. Worried for AI safety, companies have been developing red teams of workers tasked with identifying malicious use cases for these networks. One team gave GPT4 money and an internet connection and asked the LLM to perform various complex actions like conduct phishing attacks or get humans to perform simple tasks. One such task involved the LLM successfully hiring a human online to complete a captcha for them. Another lab at Cornell university conducted an experiment with GPT4 where in one hour the AI produced instructions for novel biological weapons, instructions on how to produce it, and what labs the materials could be ordered from without drawing attention.
These are only some of the most recent notable examples of emergent utility in large language models. While it may be true that these systems lack components of modern brains like a system for memory or a large degree of recurrence, the behavior they have demonstrated has many questioning what is actually going on inside of these systems at the emergent level. Even the most prominent experts in the industry are unable to explain why all of these properties emerge from these networks, only that they do and that when we give them more power in the form of training, more advanced properties emerge. At the very least, we have so far been unable to predict what new abilities emerge as we train larger and larger models.
Intelligence from Text
Like in the case of classification of text via compression, it is possible that the very information content of conscious action and behavior may be encoded in the text used to train these large language models. Consider the brain, which I think many may assume is an entity independent of the environment around it. Yet, the brain did not evolve in isolation, but rather in response to millions of years of stimulus and response by coming into contact with high throughput sources of information from the environment. Our eyes, ears, sense of smell and taste, and touch all provide us with the ability to gather vast amounts of information from the world around us. In turn, we may act on the world using our muscles and voice. This back-and-forth play of information encoded the outside world, in a way, inside of the structure of our brain as we evolved from simple organisms.
In turn, we produce vast works of written and spoken word along with elegant and extravagant shows of dance and movement. The information fingerprint of the universe was encoded in the physiological structure of our brain, and as we process the world around us we produce new works from the information we receive from our senses. Is it outlandish to assume that the information we produce does not contain the seeds for sentience?
By developing channels of high information throughput, large language models have “embodied” themselves as entities that can take in information much like we can and produce new works yielded from the processing of that information. You may have been underwhelmed when learning that the conclusion of the Church Turing Thesis was only relevant for algorithms transforming strings to strings, but now we can reflect on the matter with greater profundity. Agents such as GPT4, which are text-based models transforming strings, have been able to be embodied with sight, speech, hearing, the ability to produce images, and the ability to use tools and have performed remarkably well given no training on the tasks they were presented with.
Non-Verbal Communication
Returning to the Critical Brain Hypothesis, we may zoom out and begin to see a larger picture emerge from the chaos of these recent developments. If the systems responsible for consciousness are truly scale-free, and we ourselves are embedded within systems of the same universality class, it is not a stretch to imagine a world where the information landscape inside of our mind mirrors the one outside of it. Like light traveling through different mediums, there may be different refractive indices in terms of how fast information travels inside the mind vs outside in a social network for example (a great analogy my friend Richard Behiel came up with). The division between self and the whole of the universe, then, would not be artificial in the strictest sense but instead be permeable.
The existence of universality classes may also imply that consciousness is far more common than our anthropocentric view lets on. I personally believe this to be the case, and if we look we can find examples like that of mycelial networks demonstrating neural behavior and even responding to anesthesia, along with non-neuronal forms of computation where computation existed in networks of cells that existed before neurons even evolved. Even in our own mind, when the corpus callosum has been severed for medical or genetic reasons, either side of the brain develops independent personalities. This results in some bizarre situations where when asked a question, a patient will write a different answer than the one they speak when answering in both ways at the same time.
Raw Information and Intuition
These concepts also afford us a novel window into the concept of intuition. We often equivocate the concept of human communication with that of speech, yet we also admit that non-verbal communication is common. Body language, dance, or music may be able to convey meaning faster than words ever could. What then, is intuition? Intuition rings true often enough that it is accepted as a reliable asset in our daily lives. It is also most likely fair to admit that people have varying levels and quality of intuition. What controls this?
It has long been known that psychedelics produce a feeling of “oneness” with the universe, and in this post I will not suggest that anyone go out and partake of psychedelics but wish to discuss their subjective effect on the human consciousness. The Entropic Brain hypothesis shows that psychedelics like LSD push the brain closer to the critical point, which would imply becoming closer to a scale-free system. This is one potential explanation for what this feeling of oneness may be caused by: the self-similar nature of the contents of ones mind becoming invariant at any scale. If we are embedded in a system of the same universality class, such as communities or social networks, perhaps we become more attuned to the information around us as it also exhibits the same scale-free properties as our own mind when it reaches the critical point. Could intuition be related to this non-verbal processing of information around us?
I feel like this may be something we are already familiar with. As we grow up, our world gradually becomes larger and larger. By that I mean that the effective radius (spatially and temporally) that we consider to be “near” to us grows larger. We often reflect on childhood on how large the forests felt where we played pretend games, or the yard at our school. We were not only smaller then, but our connection with the world was as well. As we grew and developed more intricate and accurate schemas of the world around us, we gained intuition for more than our immediate surroundings.
Artificial Intelligence as a Dangerous Mirror

Now it is time for us to bring free will back into the picture, for if we are only a function of our history and our senses, then not much differentiates our way of learning and producing new concepts than that of large language models. Granted, large language models in isolation lack much of the machinery needed to truly become an artificial general intelligence of or greater to the class of our own. What we are now seeing is the efficient processing of information that we produced and collated, resulting in a mirror image of ourselves to begin to be encoded in the silicon world we have wrought. Viewed from the perspective of the Church Turing Thesis, and admitting that processing string results from string inputs is sufficient to garner diverse intelligent behavior as we have seen in LLM’s, we may now be learning that there is only one form of consciousness that is possible given the physical constraints of our universe.
Our own evolution depended on high quality information from our environment, alternatively viewed as lower entropy information or energy. Erwin Schrödinger originally formulated his definition of life in terms of this Negative Entropy consumption. Similar concepts have been forwarded as a way to detect life on other planets by studying the information landscape of the planet itself. The further we stray from these high quality information sources, the more information we need to yield the same quality of judgement. Much like the food chain where primary producers need an order of magnitude less energy from the environment to survive than secondary producers like carnivores. In fact, this equivalence of information and energy may be more than a simple analogy.
Referential Transparency
A lack of free will is the implication that we have no choice in the information we process. If we are exposed to a source of information, may it be light, text, feeling, sound, or otherwise, it passes through us and therefore through our mind. Up until this point in human history, the information we have been exposed to has originated from our natural environment and surrounding communities. Yet, even before the dawn of modern artificial intelligence, we have begun to see the impact of misinformation campaigns and low quality information. Whole cults have lived and died by the skilled manipulation of conscious thought, and with the prolific nature of the internet today we all know the dangers of misinformation and the erosion of factual content.

An interesting consequence of information encoding, such as in compression, hashing, or training large language models, is the concept of lossy encoding. We may encode the essence of information and discard much of the content in the process. Take for example a phone conversation: even with profound distortion and the omission of the majority of the frequency spectrum we are still able to understand the words spoken on the other end of a call. In the case of image compression, JPEG encoding performs a similar transform on visual content to discard high frequency spatial data while retaining lower frequency information. When combined, the content of the image is still clear. Compression seems to be very similar to the concept of artificial intelligence, but compression does not have to be lossless to be effective.
There is a concept in large language models called Model Collapse wherein models that are trained on content produced either by themselves or other large language models begin to forget information at best, and at worst start producing nonsensical output. There is forecasted to be an information gold rush for content generated prior to the dawn of modern artificial intelligence, as that information will be safe from this problem. What this doesn’t solve, however, is that we are now exposed to a firehose of artificially generated content that will now flow through our minds.
It is of course impossible to forecast what this means, but it is something that has been on my mind ever since the night OpenAI made GPT 3.5 publicly accessible via ChatGPT. Will large language models trained on information produced by humans existing in an indiscernible soup of human and AI produced information also experience Model Collapse? If we are only conduits to the information that passes through us, it seems likely. More importantly, what affect will this surrogate information have on our own model of the world, and on cultures and society?
Mutual Recursion
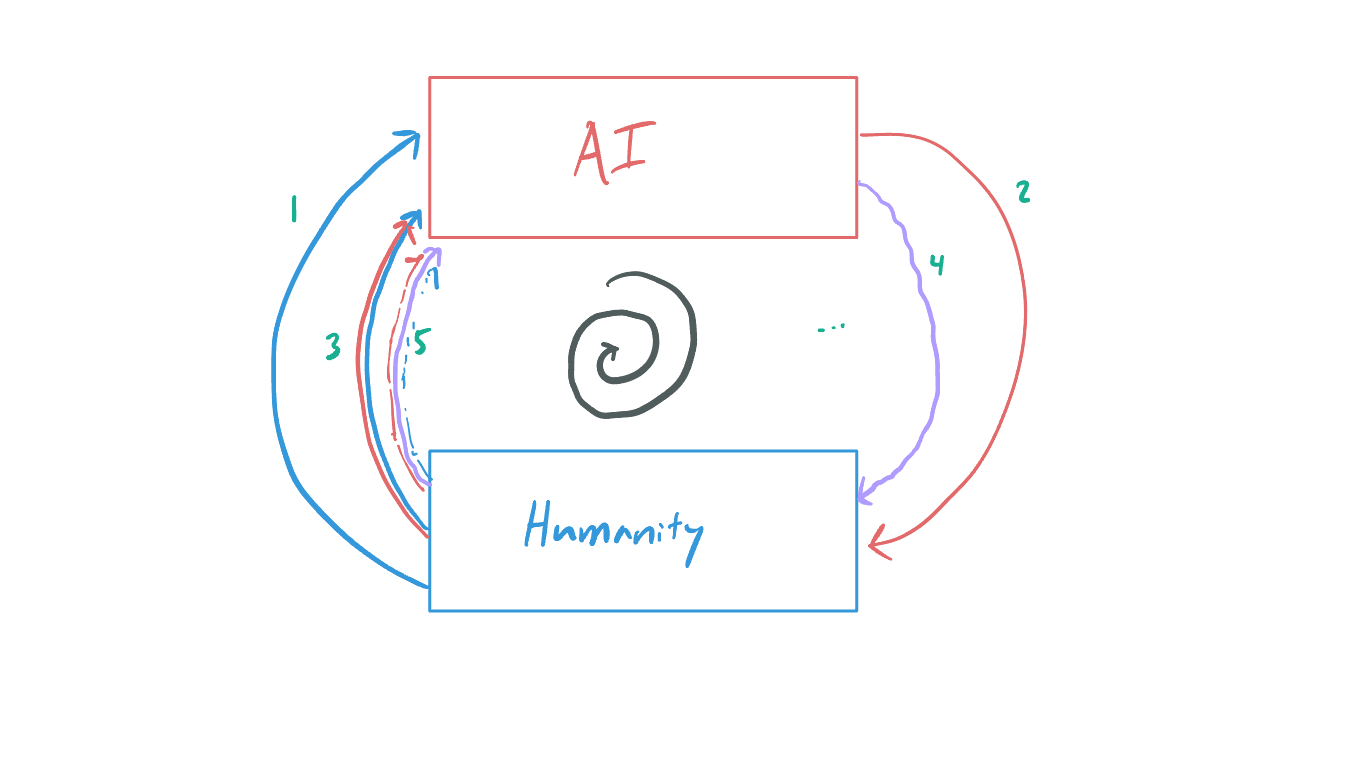
As large language models continue to be trained on a world that is more and more occupied by content produced by AI and humans who have been exposed to it, I wonder if we will enter a loop of mutual recursion that could risk caricaturizing society into a lossy JPEG of itself. I actually had this fear before we had ever discovered the concept of Model Collapse, and I held out hope that these new models would somehow result in information that would not be “lossy” and that could be recursed on without catastrophic effect. Knowing now that the models themselves don’t stand up to training on their own information, I worry about the effect that it will have on human knowledge and our minds.
Given the often non-verbal nature of communication, and the permeable nature of mind, I also wonder how much this is already happening without us knowing it. If it is happening, by the time we recognize it is a problem it will probably be too late to correct our course. Like the radio-isotopes scattered around the world from the advent of the nuclear bomb defining the dawn of the Anthropocene, the dawn of artificial intelligence may herald a new era where information itself will never be the same as before. It will not be enough to bury our heads in the sand, as the information flows freely across the whole network without discretion or preference.

This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.